ETW (Windows 용 이벤트 추적)는 사용자 모드 응용 프로그램 및 커널 모드 드라이버에서 발생하는 이벤트를 추적하고 기록하는 메커니즘을 제공합니다. ETW는 Windows 운영 체제에서 구현되며 개발자에게 빠르고 안정적이며 다양한 이벤트 추적 기능 세트를 제공합니다.
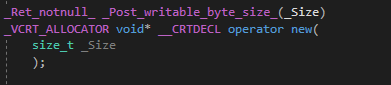
Add the __declspec(allocator) decorator to any function in your custom heap manager that returns a pointer to newly allocated heap memory. This decorator allows the tool to correctly identify the type of the memory being returned. For example:
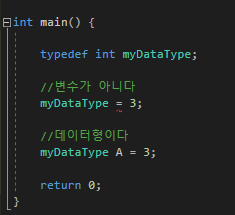
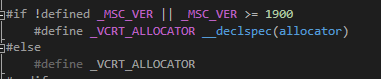
최종적으로 보아하니__declspec(allocator)는 직접적인 할당의 요청 이런게 아니라 그냥 단순 속성을 정하고
디버깅을 할때? 그런 용도로 사용되는거 같다..
V가 붙고 안붙고의 차이는 모르겠다..
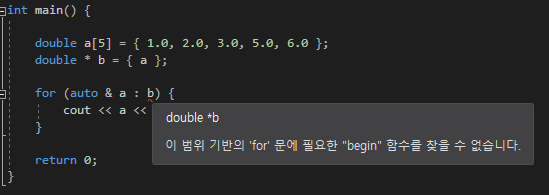
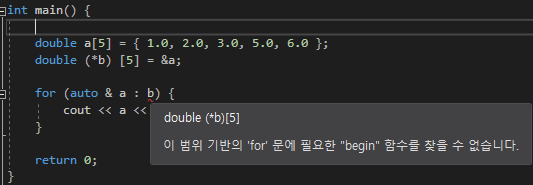
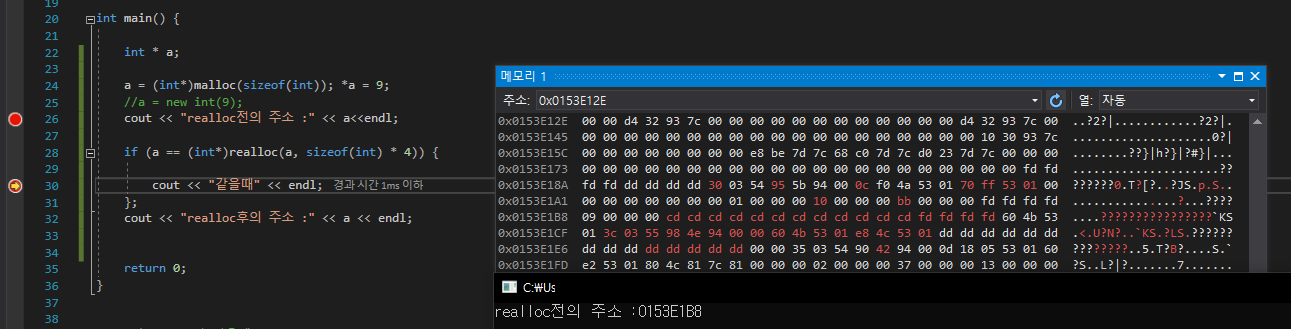
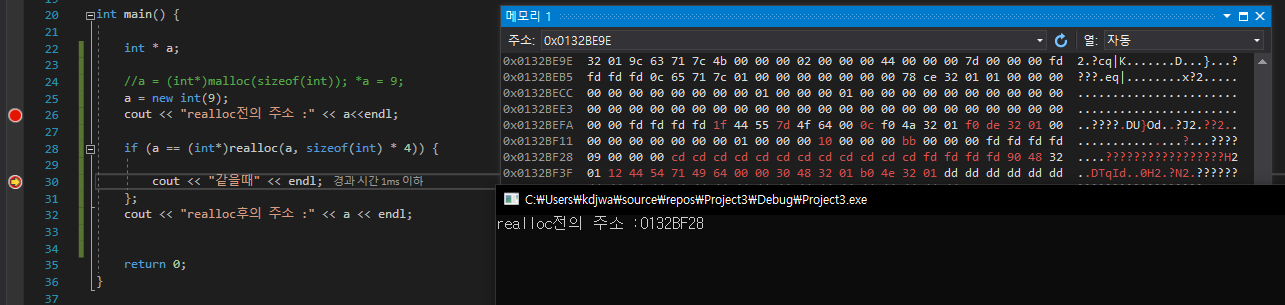
delete [ ]
new로 할당 받은 배열 포인터의 해제다
delete [ ] 포인터 로 해제를 한다
근데 사실 delete만 사용해도 해제가 된다
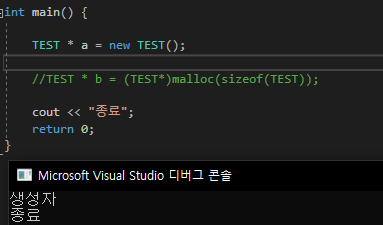
[객체 배열 같은 경우에는 소멸자 문제가 있음]
delete 전 // array를 동적 할당 받아옴 각 1, 2, 3 이 들어오는걸 볼수있다delete 후 // int * 형을 해제 시켰을 뿐인데 모두 해제가 되는 기적을 본다
근데 우리가 몇개의 배열을 할당 받은 줄 알고 시작주소만 넘겨주어도 모두 해제가 이루어지는가?? 궁금했다
일단 사전 지식을 알아야 이해할 수 있었다
1. 일단 하나의 프로그램이 시작되면 그 프로그램에게 하나의 힙메모리가 주어진다 이는 Default Heap이라 한다
(Default Heap, Default process heap 이렇게 부르는 듯 하다)
2. Default Heap은 다양한 메모리크기의 요청에 응답하려 여러 메모리의 크기로 나누어져있다
이 나누어진 메모리들을 메모리 블럭 이라 한다
3. Windows에서 이 Default Heap을 관리하는 Heap manager라는 시스템이 있다
4. 우리가 힙에 메모리할당을 요청하면 이 HeapManager가 Default Heap에서
요청한 크기에 알맞는 메모리블럭을 찾으면 그 첫번째 주소를 반환한다
5. 이때 Heap manager에 지금 할당해 준 크기를 저장한다
우리가 free나 delete로 시작주소만 넘겨도 모두 해제가 될 수 있었던 이유는 저 Heap manager에 할당해 준 크기가 저장되어 있기 때문이였다 [ 힙매니저에 저장되는 방식이라던지, 어디에있고 어떻게 관리되는 부분은 아직 내게 필요하지 않은 부분같다 ]