- 복합구문&콤마연산자
여러구문을 하나의 구문처럼 간주하는 것
중괄호를 사용해 블럭을 생성하는 방법
콤마연산자를 이용한 방법이 있다
복합구문의 예로 for의 Loop Body는 하나의 구문이어야 하는데
복합구문을 이용해 여러 구문을 실행하게 하는것이였다

콤마연산자도 마찬가지로 복합구문을 만들 수 있다
다만 밑에 처럼 선언과 같이 사용하면 변수 이름을 분리시킨다 하여 분리자 라고 한다
위에 출력값이 20 과 40이다
콤마 연산자는 왼쪽의 구문을 먼저 실행하고 오른쪽의 구문을 실행하는 시퀀스 포인트라고 한다
그래서 a = 20이 들어가고 b = 20 * 2이 되어 40이 출력이 되었다
- 관계표현식
각 연산의 결과가 bool형으로 나온다
- tpyedef ( define & using )
typedef는 기존 데이터형의 별명을 만드는 방법중 하나다( 그외 define, using)
구성이다
typedef typeName 식별자
사용하는 방식은 내가 경험하면서 알야겠지만
일단 복잡한 자료형을 간단히 나타내는데 괜찮을거 같고 자료형의 크기가 중요할때 사용해도 괜찮을거 같다
define으로도 가능하다
#define 을 한 줄에 다 쓸수 없을 때
\ 문자를 이용하여 다중 줄로 선언할 수 있다.
단, 다중 줄로 선언할 경우 마지막 줄 에는 \ 문자를 붙이지 않는다.
다만 define을 사용하면 이런문제가 있다고 한다
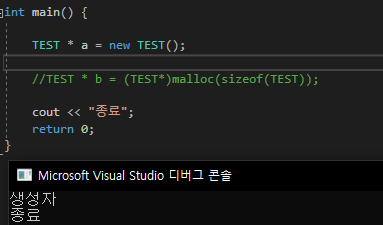
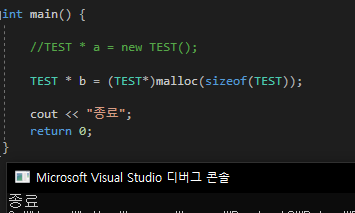
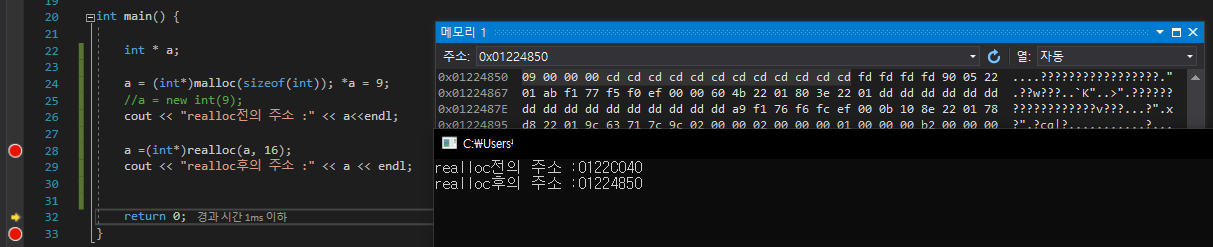
myDatatype으로 생성한 변수 b는 왜 오류가 나지 않을까?
이유는 int*가 아닌 int형으로 생성되었기 때문이다
myDatatype a, b 를 전처리기에서 변환하면
int *a, b 로 변환되기에
a는 int * 으로 생성되고
b는 int 로 생성 되었기 때문이다
그렇기에 자료형의 별칭을 만드려면 define은 비추다
그리고 typedef말고 using을 사용해서도 정의할 수 있다
그럼 typedef와 using의 차이는 무엇인가?
templete의 사용 유무다
using 같은 경우 템플릿을 사용가능하나
typedef 같은 경우 템플릿을 사용하지 못한다
- 문자열 비교
c 스타일 - strcmp( const char * 1, const char * 2) 사용
훨씬 편한 string은 == 사용하여 비교 가능
- while
루프 몸체와 조건 검사부분으로 이루어진 반복문
for과 같이 조건이 true면 루프몸체를 실행한다
- do while
while로직이 "조건검사 ─> 루프몸체 실행" 이라면
do while은 "루프몸체 실행 ─> 조건검사" 으로 실행부터하고 검사한다
조건이 true면 다시 몸체 실행을 하는 것 도 같다
- Range based for loop
C+11에서 추가된 for의 형태
조건부 구성이다
for( range_declaration : range_expression )
range_declaration - 변수의 선언, range_expression의 배열 원소 타입으로 지정한다
range_expression - begin( ), end( ) 함수가 정의된 객체 혹은 braced init list
braced init list는 중괄호를 사용한 초기화 문법인데 아마 이걸 사용한 데이터를 뜻하지 않나 싶다
단순 동적배열에 begin이나 end가 내부적으로 정의 되어 있는지 모르겠지만
(아마 안되는 듯 싶은데.. 검증해야한다)
일단 braced init list내에 속해 있기에 가능한거같다
밑의 링크는 braced init list
https://en.cppreference.com/w/cpp/language/list_initialization
range_declartion은 range_expression원소와 자료형이 달라도 자동적으로 캐스팅을 해줌으로
같지는 않더라도 최소 캐스팅이 가능한 자료형이여야한다
밑의 링크는 ranged based for이 설명된 사이트
https://en.cppreference.com/w/cpp/language/range-for
밑의 Explanation은 위의 사이트에서 나온 설명이다
정말 기존 for문에서 새로운 코드가 아니라 내부적으로는 위처럼 기존 for문이 작동하나 보다
보통 밑의 코드처럼 사용하는데
auto를 이용해 자료형을 받는데 편리함을 취하고
&를 이용해 복사비용을 줄이면서 값까지 변경 할 수 있는 방식을 많이 사용하는 듯 하다
조건부 배열 부분에 배열이름을 사용했다
처음에는 배열이름은 곧 주소이기도 하니까 포인터를 사용 할 수 있지 않을까 생각을 했지만
그렇게 되면 for문은 그 주소가 가진 배열의 크기를 알지 못하기에 사용 할 수 없다
그렇기 때문에 range_expression부분에 들어오는 데이터에 크기를 알수있는 데이터만 가능한가보다
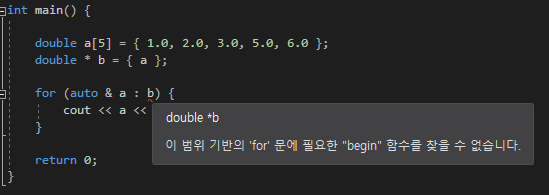
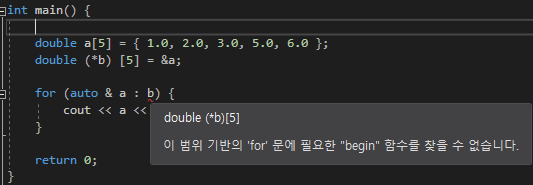
그러다 함수내에서 매개변수 받아 ㅅㅂ 어떻게 사용하지? 하다가 이렇게 자료형을 구체적으로 적어주는 걸 생각했다
근데 이렇게 사용하다가는 너무 불편할거 같아 템플릿을 이용했다
braced init list 에 있는것중 이런것도 있어 가능한지 확인했다
'C++ > [책] C++ 기초 플러스' 카테고리의 다른 글
| [ 328p ~ 372p ] cctype.h, 삼항연산자, switchcase, break&continue, 간단한 파일I/O ///스트림 (0) | 2021.07.08 |
|---|---|
| [ 281p ~ 327p ] EOF, 2차원배열, If, 논리표현식 (0) | 2021.07.07 |
| [ 220p ~ 253p ] stl vector & stl array, 표현식, for, 증가&감소 연산자, 부수효과&시퀀스 포인트, 접두어 접미어 방식 (0) | 2021.07.03 |
| [ 210p ~ 219p ] 도트 멤버 연산자 & 화살표 멤버 연산자, 데이터의 저장공간, 포인터 장난 (0) | 2021.07.01 |
| [ 203p ~ 209p ] 문자열 상수 (0) | 2021.06.30 |