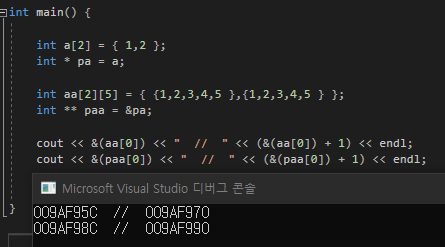
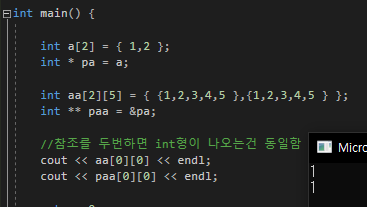
- 배열참조형
참조형을 담는 배열은 생성할 수 없다

단 배열자료형의 참조형은 가능하다

- 디폴트 매개변수
C++에서 새로 생겨났으며
매개변수에 기본으로 사용하는 값을 지정하여
함수 사용시 설정한 해당 매개변수를 기술하지 않으면 설정한 값으로 매개변수가 입력되는 기능
밑의 int b처럼 기본값을 설정해주면 된다

디폴트 매개변수은 규칙은 무조건 오른쪽에서 왼쪽으로 기술해야한다

- 오버로딩
같은 함수의 이름으로 다른 매개변수, 다른 함수내용 을 정의 할 수 있는 기능
이 오버로딩은 객체프로그래밍의 다형성을 나타내는 기능중 하나이다

이 설명을 프로그래밍으로 나타내면
같은 종의 생물 = 같은 식별자
크기, 형태, 색깔 = 매개변수 리스트, 반환 자료형, 함수 내용 이라고 생각한다

오버로딩을 할 때 주의 할 점은 매개변수 리스트는 필수로 무조건 달라야한다
반환 자료형이나 함수내용이 달라도 매개변수 리스트가 같으면 성립이 되지 않는다

이와 몇가지로 안되는 경우가 있는데
보통 함수에 이미 본문이 있을 때 이다
- 매개변수의 const


코드상으로는 문제가 없지만 실행시 오류가 난다
이유는 같은 코드라고 컴파일러가 인식하기 때문
이는 int a나 const int a나 lvalue, rvalue모두 가능한 공통점 때문에 같은 코드라고 인식하는듯 하다
단 참조일 경우에는 다르다

참조일 경우에는 lvalue, rvalue 확실히 나누어지기 때문에 가능한 듯하다
※클래스의 멤버함수에서는 이런식으로 가능하다

- * 와 [ ]

내가 생각하기로는 [ ]은 매개변수로 들어갈때 컴파일러가 포인터형으로 변환하는데
이때문에 같은 코드로 인식되어 실행이 불가능한 듯하다
- 이름장식
c++은 오버로딩된 함수중 어떤것이 맞는지 어떻게 추적하냐면
이름장식(Name mangling)을 사용한다고 한다
함수 원형에 지정되어 있는 형식을 암호화 한다고 한다
예를들어
long Test(int) 를 암호화로 ?test@@YAXH@z
이런식으로 매개변수의 개수와 데이터형을 암호화한다고 한다
[컴파일러마다 암호 규칙이 다르다고한다]
이렇게 다른 암호화명으로 찾는듯 하다
'C++ > [책] C++ 기초 플러스' 카테고리의 다른 글
| ※[ 535p ~ 558p ] 오버로딩분석, decltype, 후위반환타입 (0) | 2021.08.12 |
|---|---|
| [ 517p ~ 534p ] 함수 템플릿, 템플릿 오버로딩, 구체화, 명시적 특수화 (0) | 2021.08.11 |
| [ 467p ~ 485p ] inline, 참조변수 (0) | 2021.07.18 |
| [ 443p ~ 466p ] 함수포인터 (0) | 2021.07.16 |
| [ 413p ~ 442p ] 함수의 매개변수, 재귀호출 (0) | 2021.07.15 |