

||문제 이해
유저는 여러명에게 신고할 수 있지만 한명의 유저에 대해 신고 스택을 1만 쌓을수 있다.
k번 이상 신고 된 유저는 정지당하고 그 유저를 신고한 사람들에게 정지 완료 처리 메일을 보내려고 한다.
각 사람들마다 정지 완료 처리 메일을 받은 개수를 구해라
||해결 계획
1.
report를 순차로 돌면서 map<"신고 당한 사람", set<"신고를 한 사람들">> 형식으로 저장한다.
여기서 vector<"신고를 한 사람들">.size( )가 곧 신고 받은 횟수이다.
2.
위에 저장한 map을 돌면서 신고 횟수가 k개 이상인지 확인한다.
이용 정지 조건에 충족한다면 set<"신고를 한 사람들">을 모두 탐색하면서
map<"처리 메일을 받을 사람", 그 개수>에 저장한다.
3.
위에서 id_list를 순차 탐색하면서 위에서 새로 저장한 map에서 찾아본다.
위에서 저장되지 않았으면 0이니, 0을 answer에 넣어주고
따로 개수가 저장되어있으면 그 개수를 answer에 넣어준다.
||계획 검증
중요한 입력에는 id_list와 report가 있는데
id_list < 1'000, report <= 200'000 이고
id_list는 3번에 순차탐색하는 것이라 가볍게 넘어갈 수 있고
가장 입력값이 큰 report에 관련있는 1번만 검사 해보려한다.
1번에서 중요했던건 신고자와 신고당한자를 나눈것이였다.
substr은 O(n) = 21
n은 원본 문자열의 길이인데 최대 21이다.
find는 O(nm) = 21
n은 원본 문자열의 길이인데 최대 21이다.
m은 찾으려는 문자열의 길이인데 나는 공백을 찾을것이므로 1이다.
이를 총 두번씩할 예정이기에 42 + 42 = 84
그리고 이는 report개수만큼 반복된다.
84 * 200'000 = 16'800'000 로 충분한것 같다!
||구현
#include <bits/stdc++.h>
using namespace std;
map <string,set<string>> m;
map <string,int> mm;
vector<int> solution(vector<string> id_list, vector<string> report, int k) {
vector<int> answer;
//1. <신고당하는자, 신고한자들> 저장
int idx;
string a, b;
for (const auto & d : report)
{
a = d.substr(0, idx = d.find(" "));
b = d.substr(idx = d.find(" ") + 1);
m[b].insert(a);
}
//2.정지 이용자 찾고 찾으면 map<신고한자들,처리메일개수>에 개수를 올린다.
for(auto d: m)
{
if(k <= d.second.size())
{
for(auto e : d.second) ++mm[e];
}
}
//3.id_list의 사용자들의 개수를 answer에 넣는다.
for(auto d: id_list)
{
if (mm[d] == 0) answer.push_back(0);
else answer.push_back(mm[d]);
}
return answer;
}||되돌아보기
해결 방법을 써 놔도 정리가 안돼서 저장해야할 것을 적어봤었다.
처음에는 신고 당한자, 신고를 한자들, 신고 당한자의 횟수
근데 여기서 신고 당한자의 횟수는 즉 신고를 한자들의 개수와 동일했다!
그래서 나는 사실 이 두개를 하나로 저장할 수 있었다!
이 때문에 좀 구현하기 수월했다.
||개선 코드
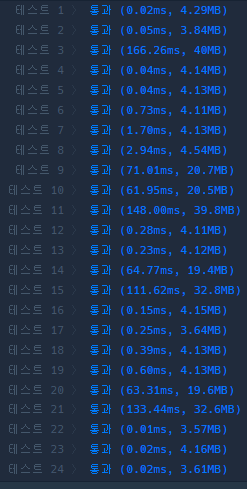
이번에 어디서 개선시킬수 있을까 생각했는데
아마 report의 문자열을 나누는 지점이 아닐까 싶었다.
그래서 고민도 해보고 여러 사람들의 코드도 보았는데
코드는 간단한게 있었지만 시간은 내게 조금더 빨랐거나 비슷했다.
1. 이렇게 stringstream을 사용 하여 편하게 나눌 수 있었다.
for (const auto& s : report) {
stringstream in(s);
string a, b; in >> a >> b;
v.push_back({ Conv[a], Conv[b] });
}이러한 스트림을 이용한건 정말 편하지만
substr와 find를 이용하여 나눈것이 미세하게 빨랐다.
2. sort 후 unique로 중복제거.
sort(s.begin, s.end);
s.erase(unique(s.begin(), s.end()), s.end());나는 이러한 중복제거를 예외처리하려고 set에 저장하여 중복을 회피했다.
'코딩 테스트 > 알고리즘 풀이' 카테고리의 다른 글
| [백준 - 1560] 비숍 (0) | 2022.12.03 |
|---|---|
| [알고스팟 - PICNIC] 소풍 (0) | 2022.12.02 |
| [프로그래머스] 신규 아이디 추천 (0) | 2022.09.16 |
| [백준 - 2437] 저울 (0) | 2022.09.07 |
| [프로그래머스] 숫자 문자열과 영단어 (0) | 2022.09.02 |
| [백준 - 2908] 상수 (0) | 2022.09.01 |
| [백준 - 17509] And the Winner Is... Ourselves! (0) | 2022.09.01 |
| [백준 - 1449] 수리공 항승 (0) | 2022.09.01 |