

||문제 이해
숫자와 영문이 섞인 문자열을 숫자로 변경하여 리턴해라.
||해결 계획
pair<int , int> p라는 변수에 first는 인덱스, second는 해당 숫자를 저장할 것이다.
1번 for문에는 단어만을 검색하여 p에 저장,
2번 for문 에는 숫자만을 검색하여 p에 저장
그 후 인덱스(fisrt)를 기준으로 오름차순 sort 하여 순서대로 합쳐 리턴한다.
||계획 검증
1번 for문에는 string::find를 사용할 것이기 때문에 가장 큰 문자 길이 eight의 5를 곱했다.
find : 시간 복잡도는 찾으려는 문자 길이 * 원본 문자열 길이
단어 개수 * find = 10 * n * 5 = O(50 * n)
2번 for문에는 문자열 길이만큼 반복하여 저장한다 = O(n)
즉, O(50 * n + n) 이므로 최대 50 * 50 + 50 = 2550 번 연산으로 끝낼 수 있다.
||오답 원인
1. while과 find의 환장의 조합 - 1
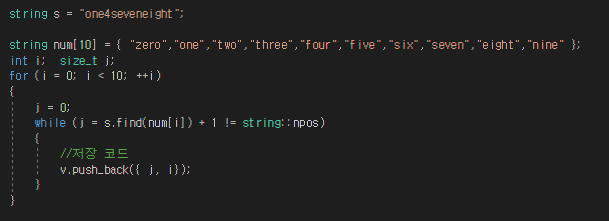
이는 무한 루프다.
find가 계속 인덱스 0 부터 찾는 것을 막기 위해 j + 1을 했었는데 사용하지 않은 어리석은 케이스
find는 항상 인덱스 0 부터 찾을 것이다. one을 찾아도 다음에도 같이 ond을 찾을 것이다.....
이 때문에 많은 시간 소모를 했다...
2. while과 find의 환장의 조합 - 2

찾지 못하면 npos를 반환하는 find로 못 찾을 때까지 반복하여
반복문 내부에서 찾은 영어단어를 숫자로 변환하여 저장하려고 했다.
근데 만약 s가 "one4zerotwo"라 한다면 이 코드는 one을 저장할 수 없다.
왜냐면 처음 찾은 one이 인덱스 0을 반환한다, 이는 즉 false와 같으므로 반복문 내부에 들어가지 못하여 저장할 수 없다.
2. 내 착각
어찌어찌 저 for문은 넘어가고
처음에는 문자열을 순차적으로 탐색하여 문자와 숫자 한 번에 변환하여 저장하려고 했다.
string s = "one4twozero";
for(int i = 0; i < s.size(); ++i)
{
if(s[i] 가 문자면)
{
for( 0 ~ 10 )
{
if(s.find(모든 문자) != npos)
{
찾으면 저장 후 break
}
}
}
if(s[i] 가 숫자면)
{
숫자 - '0' 후 저장
}
}근데 여기서 웃긴 게 처음 탐색인 i가 0일 때 찾는 문자는 'o'이다.
그러면 이 i부터 one인지, two인지, three인지 탐색하여 맞는 것으로 저장한다.
여기서 나는 one을 변환했으니까 다음 탐색은 4겠지??라고 무의식 속에 사로잡혀있었다.
근데 다음 탐색은 놀랍게도 'n'이다.
그러면 n부터 탐색된 two가 나와 1 다음 2가 나오게 된 것 ㅋㅋㅋ
좀 더 자세히 생각해야겠다..
||구현
#include <bits/stdc++.h>
#include <stdlib.h>
using namespace std;
const string num[10] = { "zero","one","two","three","four","five","six","seven","eight","nine" };
typedef pair<int, int> pii;
vector<pii> v;
int solution(string s) {
int answer = 0;
//문자만 변환하는 곳
int i, j;
size_t t;
for (i = 0; i < 10; ++i)
{
t = 0;
do
{
t = s.find(num[i], t);
if (t != string::npos)
{
v.push_back({ t++, i });
}
else break;
} while (true);
}
//숫자만 변환하는 곳
for (i = 0; i < s.size(); ++i)
{
//숫자가 영어보다 아스키코드가 작음
if (s[i] <= '9')
{
v.push_back({ i,s[i] - '0' });
}
}
sort(v.begin(), v.end());
for (const auto & d : v)
{
answer = answer * 10 + d.second;
}
return answer;
}||되돌아보기
처음에 한 번에 저장하려는 풀이가 정확하게 그려지지 않음에도 쉬워 보인다고코드를 작성하여
이것저것 시간을 많이 소모했고 find도 내가 자세히 알지 못하여 시간을 소모했다..
많은 반성을 하게 됐다..
이번에 풀게 될 수 있었던 핵심은 통일이다.
문자 먼저 모두 pair<인덱스(int),해당 숫자(int)>형으로 저장하고
그다음 숫자도 따로 모두 pair<인덱스(int),해당 숫자(int)>형으로 저장하여 통일했다.
그 후에는 sort 하고 출력하면 끝!
다른 타입이 섞여있다면 한 번에 하려 하지 말고 하나의 타입씩 연산하는 것도 괜찮았다
||개선 코드
#include <bits/stdc++.h>
using namespace std;
int solution(string s) {
s = regex_replace(s, regex("zero"), "0");
s = regex_replace(s, regex("one"), "1");
s = regex_replace(s, regex("two"), "2");
s = regex_replace(s, regex("three"), "3");
s = regex_replace(s, regex("four"), "4");
s = regex_replace(s, regex("five"), "5");
s = regex_replace(s, regex("six"), "6");
s = regex_replace(s, regex("seven"), "7");
s = regex_replace(s, regex("eight"), "8");
s = regex_replace(s, regex("nine"), "9");
return stoi(s);
}저 regex는 처음 보는데 대강 보니까 유용하게 쓸 수 있을 것 같다.
다음에 좀 공부해야겠다.
'코딩 테스트 > 알고리즘 풀이' 카테고리의 다른 글
| [알고스팟 - PICNIC] 소풍 (0) | 2022.12.02 |
|---|---|
| [프로그래머스] 신규 아이디 추천 (0) | 2022.09.16 |
| [백준 - 2437] 저울 (0) | 2022.09.07 |
| [프로그래머스] 신고 결과 받기 (0) | 2022.09.03 |
| [백준 - 2908] 상수 (0) | 2022.09.01 |
| [백준 - 17509] And the Winner Is... Ourselves! (0) | 2022.09.01 |
| [백준 - 1449] 수리공 항승 (0) | 2022.09.01 |
| [백준 - 2503] 숫자 야구 (0) | 2022.08.31 |