- inline함수
inline함수는 프로그램의 실행 속도를 높이기 위해 c++에서 새로 보강된것
함수가 하나 생성되면 함수의 시작 주소가 있을것이며
함수가 호출 될때 그 시작주소로 가서 실행 후 다시 원래 있던 주소로 돌아갈것이다
이를 더 자세히 하면
1. 함수 호출 명령
2. 함수 호출 명령 다음의 코드 주소를 메모리에 저장 [함수 종료 후 다시 돌아와야하니까]
3. 호출하려는 함수의 매개변수 복사 [파라미터에 넣어야하니까]
4. 호출하려는 함수의 주소로 점프
5. 함수 코드 수행
6. 함수 종료시 함수의 리턴값을 레지스터에 복사
7. 저장해 두었던 코드 주소로 점프
이러한 과정들이 있는데
inline은 이러한 문제를 어느정도 해결해준다
바로 함수를 호출할때 원본함수코드를 그냥 그자리에 붙여넣어서
이동할 필요 없이 그 자리에서 읽고 처리한다
define과 비슷한 부분이다

이렇게 작성한 코드를 inline화 시키면
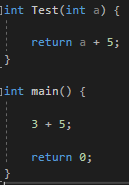
이런식으로 원본 코드가 온다는 말이다
inline의 사용법은 inline 이라는 키워드를 함수의 선언이나 정의 앞에 붙여주면 된다

inline이 속도는 굉장히 빨라지겠지만 만약 함수의 크기가 크다면
붙여지는 코드의 양도 그만큼 커져 프로그램이 무거워질 것이다 [ ※재귀함수는 불가능 ]
그렇기 때문에 그 기준을 잘 잡아야 하는데
이 기준은 다행히도 컴파일러가 알아서 해준다
얼마나 알아서 잘 해주냐면
우리가 inline키워드를 사용해도 컴파일러 판단에 부합하지 않으면 inline화 해주지 않는다
우리가 inline키워드를 사용하지 않아도 컴파일러 판단에 inline화 해준다
그러므로 우리가 inline키워드를 사용한다는것은 약간 요청보단 이건 어때? 라는 권유의 느낌 같다.
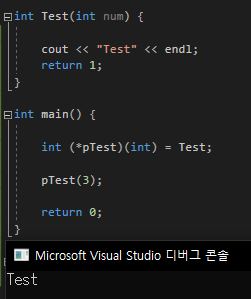
그리구 추가로 inline함수의 함수포인터를 사용해서 함수가 호출되었을때는 일반함수로 호출이 된다
이쯤 보면 매크로와 상당히 비슷한데
차이랄게 있다면
매크로는 단순히 코드를 변환시키는거지 값을 전달하지않는다

매크로 함수같은경우 값이 전달되는게아니라 문자 치환이여서
++a * ++a 가 되므로 "++" 연산자가 두번 실행된 후 곱셈이 진행되어 3 * 3으로 9가 나온다.
- 참조변수
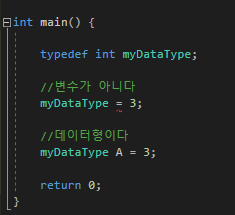
c++에 새로운 복합자료형이다
reference라고도 하며 미리 정의된 어떤 변수의 식별자 대신 쓸 수 있다
이 대신 사용한다는 것은 주소를 참조하여 사용한다는 의미이다 => 복사비용문제 해결
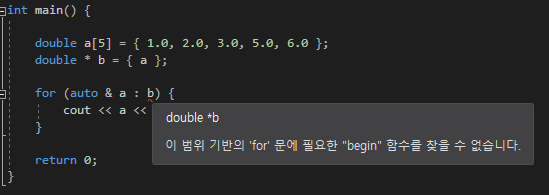
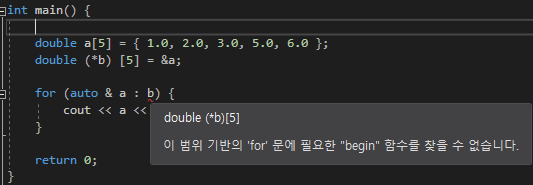
생성은 &를 붙여 생성한다


오른쪽 처럼 선언과 동시에 정의를 해주지않으면 생성 할 수 없으며
나중에 참조하는 변수를 바꿀수 없다
이 참조변수의 주된 용도는 매개변수에 사용하는데
기존 함수가 호출될때 매개변수에 들어온 값을 복사하여 사용하는데
이 참조형을 매개변수로 사용할시에 함수는 같은 주소를 가지고 있는 매개변수를 받기때문에 원본 데이터를 다룰수있다

만약 참조형에 다른 자료형이나 상수가 들어가면 에러가 난다
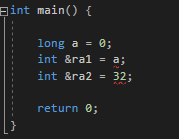
하지만 const를 사용하면 허용이 된다

이는 const일 경우 컴파일러는 임시변수를 생성하기 때문이다
long a를 int형으로 변환시켜 만든 임시변수 를 ra1가 참조하고
ra2 에 들어가는 상수 32를 가지고 있는 int형 임시변수 를 ra2가 참조하게 만든것이다
참조형은 참조 대상과 주소 값이 같다는 특성 때문에 참조 대상의 '별칭(alias)'이라고도 불린다.
나무라서 좀 그렇지만 배울게 많다..
https://namu.wiki/w/%EC%B0%B8%EC%A1%B0%EC%97%90%20%EC%9D%98%ED%95%9C%20%ED%98%B8%EC%B6%9C
'C++ > [책] C++ 기초 플러스' 카테고리의 다른 글
| [ 517p ~ 534p ] 함수 템플릿, 템플릿 오버로딩, 구체화, 명시적 특수화 (0) | 2021.08.11 |
|---|---|
| [ 486p ~ 517p ] 배열참조형, 디폴트 매개변수, 오버로딩, Name mangling (0) | 2021.07.29 |
| [ 443p ~ 466p ] 함수포인터 (0) | 2021.07.16 |
| [ 413p ~ 442p ] 함수의 매개변수, 재귀호출 (0) | 2021.07.15 |
| [ 373p ~ 412p ] 함수, 매개변수 (0) | 2021.07.09 |