
개요
이번에 한 알고리즘 풀이에 사용되어서 공부하게 됐다.
https://www.acmicpc.net/problem/1715
1715번: 카드 정렬하기
정렬된 두 묶음의 숫자 카드가 있다고 하자. 각 묶음의 카드의 수를 A, B라 하면 보통 두 묶음을 합쳐서 하나로 만드는 데에는 A+B 번의 비교를 해야 한다. 이를테면, 20장의 숫자 카드 묶음과 30장
www.acmicpc.net
특징
힙은 이진트리의 종류중 하나이고 최대 힙, 최소 힙 으로 나누어져 있고
루트 노드가 언제나 그 트리의 최대값 혹은 최소값을 가진다는 특성이 있다.
이는 루트 노드 뿐만 아니라
루트노드가 최대값이라면 모든 노드가 자기 자식 노드보다 큰 값을 가지고 있고 = 최대 트리
루트노드가 최소값이라면 모든 노드가 자기 자식 노드보다 작은 값을 가지고 있다. = 최소 트리
또한 완전 이진 트리어야 한다. 중간에 빈 노드가 없다는게 중요!
그래서 완전 이진 트리이기 때문에 배열로 구현하는게 정말 효율적이다.
배열로 구현하는게 정말 효율적이다 :
● 자기의 Index로 자식의 Index를 알수있고 그 반대도 가능하다
● 또한 특정 레벨의 최대 노드 개수도 간단히 구할 수 있다.
●
배열의 단점인 중간에 값을 삽입하는 일이 없다.● 인덱스 순서대로 삽입하면 트리가 기울어질일이 없다.
주의 할 것은 이 힙은 최대, 최소에 중점을 두었기 때문에
그 나머지 노드에 대해서는 느슨한 정렬 상태를 유지한다. [이진 탐색 불가능]
최대 트리여도 하위 레벨 노드보다 작을수도, 최소 트리라면 하위 레벨 노드보다 클 수도 있다는 말이다.
암튼 정리하면
최대 힙 = 최대 트리 + 완전 이진 트리
최소 힙 = 최소 트리 + 완전 이진 트리
왜 사용하는가?
오직 어떤 최소값이나 최대값을 얻고 싶다면 리스트나 배열을 한번 정렬해서 앞에서 쭉 가져오면 된다.
하지만 어떤 데이터가 추가되어 다시 정렬 후 최대, 최소 값을 가져올때 이 힙이 굉장히 강력한데
힙을 이용한 priority_queue과 퀵정렬을 사용하여 실험해 보았다.
데이터를 계속 추가하면서 내림차순으로 정렬하여 최대값을 출력한다.
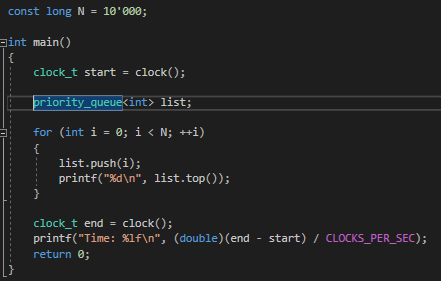
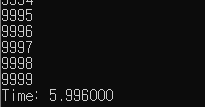

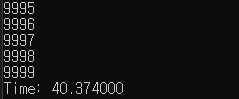
암튼 데이터의 추가,삭제가 빈번할 때 최대, 최소 값을 얻고자 할 때 사용해야겠다 !
구현
생성 & 소멸

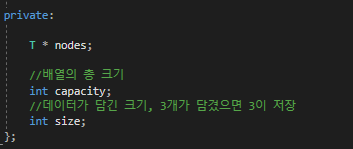
Private 멤버

데이터 삽입

데이터 삭제
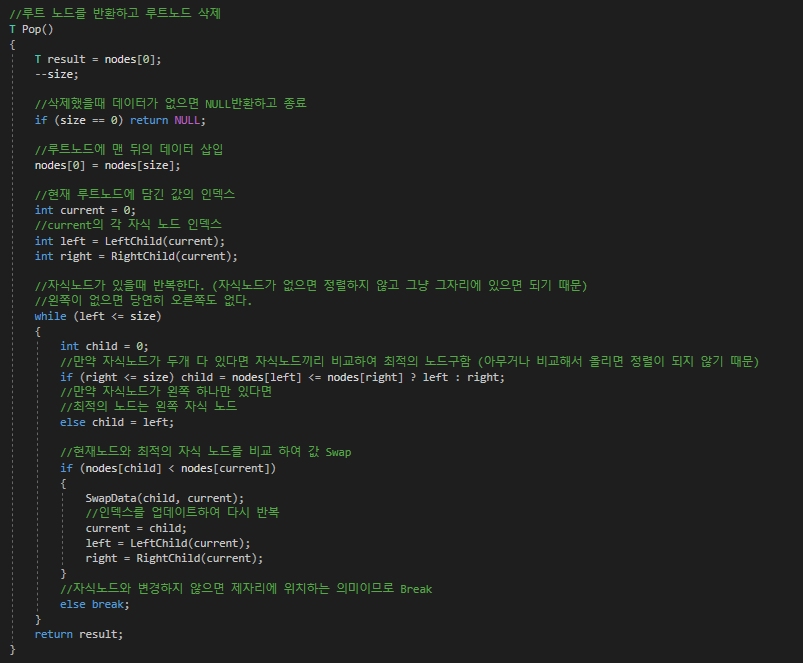
결론
사용처
언리얼에서 포스트 프로세스라는 기능이 있는데 여기서 우선 순위를 정하여 렌더링 순서를 정할 수 가 있다.
이때 힙을 이용하면 편리할거 같다.
나머지는 또 생각해봐야겠다.
추가
stl::prioirity_queue & stl::make_heap
stl에 저 두가지가 비슷하게 쓰이는데
N3337에서 priority_queue은 힙으로 구현되고 생성자로 make_heap이 사용 된다고 한다.

코드 내 주석으로 보면 복사나 이동이 필요할때 make_heap이 사용된다.
가장 뚜렷한 차이는
make_heap같은 경우는 이미 있던 컨테이너를 힙구조로 만들기때문에
루트 노드 뿐만아니라 다른 노드에도 접근이 가능할수도 있다는 것과
priority_queue같은 경우는 어댑터 클래스로 public한 함수가 루트 노드에만 접근이 가능하다는 점이 있다.
어떻게 보면 힙의 캡슐화 같은 느낌이 더 강하게 든다.
https://stackoverflow.com/questions/11266360/when-should-i-use-make-heap-vs-priority-queue
When should I use make_heap vs. Priority Queue?
I have a vector that I want to use to create a heap. I'm not sure if I should use the C++ make_heap function or put my vector in a priority queue? Which is better in terms of performance? When shou...
stackoverflow.com
https://leeminju531.tistory.com/20?category=979284
(C++ STL) priority_queue, make_heap 제대로 이해하기(1)
http://www.cplusplus.com/reference/algorithm/make_heap/ make_heap - C++ Reference custom (2)template void make_heap (RandomAccessIterator first, RandomAccessIterator last, Compare comp ); www.cplusp..
leeminju531.tistory.com
'코딩 테스트 > 자료구조' 카테고리의 다른 글
| Queue (0) | 2026.01.13 |
|---|---|
| Stack (0) | 2026.01.12 |
| Linked List (0) | 2026.01.07 |
| Vector (1) | 2026.01.07 |
| String & Vector (0) | 2025.05.18 |