

Queue
큐는 스택과 달리 출구는 앞에, 입구는 뒤에 있는 컨테이너다.
때문에 처음 삽입된 원소가 처음 나오게 강제되는 구조를 가진다.
(First in First out)
이렇게 강제되는 구조이기 때문에 따라오는 특징들이다.
- 중간 접근 불가
- 순서 변경 불가
이전에 스택에서 알아보았던 특징과 똑같은데, 이는 큐와 스택의 장,단점이 모두 같다는 뜻이다!
스택과 겹치는 부분이 많지만 그래도 특징을 정리해보면 아래와 같은 특징이 있다.
- Random Access를 허용하지 않는다.
때문에 데이터 처리 순서가 변경되는걸 강제로 막아, 데이터의 순차적 처리 흐름을 보장한다.
(스택은 역순의 처리 흐름) - 위처럼 데이터 처리의 흐름이 보장되기 때문에 데이터의 흐름 파악과 디버깅에 효과적이다.
스택과 마찬가지로 무엇을 할 수 없게 제한하는 것이,
데이터의 흐름을 더 명확하게 안내해주는 강력한 기능이라는 것을 더 알게 해주는 컨테이너다.
시간 복잡도
- 탐색 : 탐색을 목적으로 설계된 자료구조가 아니다.
- (첫번째 원소) 접근 : O(1)
내부적으로 항상 맨 앞 원소의 위치를 알고 있으므로 항상 상수 시간을 가진다. - (첫번째 원소) 삭제 : O(1)
접근하여 삭제한다. - (뒤쪽에) 삽입 : O(1)
뒤쪽에 바로 삽입하면 된다.
다만 배열 기반 큐인 경우에는 재할당 복사 과정을 생각하여 Amorized O(1)로도 볼 수 있다.
언제 사용해야 하는가
큐는 아무래도 순서가 의미를 가지는 데이터 처리에 매우 강하다.
즉, 작업을 순서대로 처리해야 할 때 강력하다.
- 순차적인 작업 예약
프린터의 인쇄 대기열이나 티켓 예매 시스템처럼 '줄 서기'가 필요한 경우. - 프로세스 관리
OS의 스케줄링(먼저 요청된 프로세스부터 처리)이나 쓰레드 풀(Thread Pool)의 작업 큐. - 데이터 버퍼링
네트워크 패킷 처리나 스트리밍 데이터를 일시적으로 저장했다가 순차적으로 처리해야 할 때. - BFS
가까운 노드부터 차례대로 방문해야 하는 그래프 탐색에 최적화되어 있다.
이렇게 먼저 들어온 요청을 먼저 처리해야 하는 상황에 적합하다.
언제 피해야 하는가
순서적 흐름이 아닌 경우에 해당된다.
- 최근 데이터가 더 중요할 때
큐는 가장 오래된 데이터를 우선 처리하므로, 최근 데이터가 우선되어야 하는 상황에는 맞지 않는다.
이 경우에는 스택이나 덱을 이용한다. - 우선순위가 제각각일 때
데이터가 들어온 순서보다 '중요도'가 더 중요하다면 일반적인 큐는 부적합하다.
이때는 우선순위 큐 라는걸 사용해야 한다. - 중간 데이터 수정이 빈번할 때
큐는 중간에 있는 원소를 건드리는 순간 자료구조로서의 의미를 잃는다. - 양방향 출입이 필요할 때
앞뒤 양쪽에서 삽입/삭제가 모두 일어나야 한다면 덱을 고려하는게 좋다.
구현
큐도 마찬가지로 리스트 구현은 잘 사용하지 않는다. (캐시 때문인지 그냥 리스트를 잘 사용하지 않음..)
큐의 구조상 뒤에서 채우고, 앞에는 비우고 하다 보니까 앞에 사용하지 못하는 데이터가 많아진다.
그래서 이 앞의 칸도 사용해보자! 해서 나온게 원형 큐다.
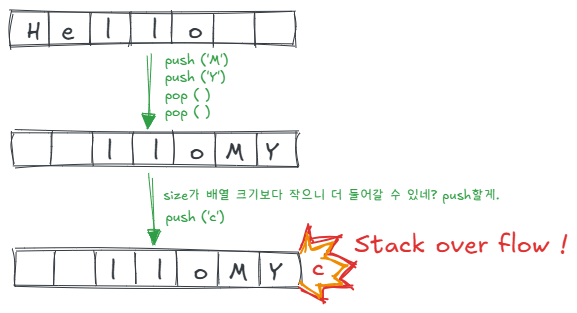
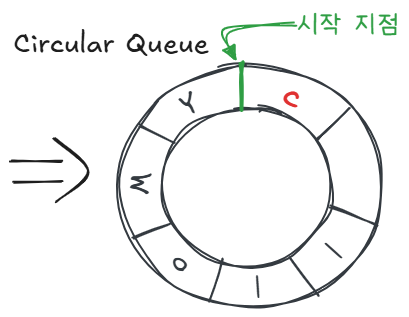
그래서 기본 배열 기반 큐보다는 원형 큐가 쓸모있기 때문에 원형큐를 구현해본다.
멤버 변수
T* data; // 실제 데이터를 저장할 배열
int capacity; // 큐의 최대 크기
int front; // 다음에 꺼낼 요소의 인덱스
int rear; // 다음에 삽입할 위치의 인덱스
int count; // 현재 큐에 들어있는 요소 수
삽입
bool push(const T& value)
{
// 가득 찬 큐인지 확인
if (count == capacity) reteurn false;
// rear 위치에 값 저장
data[rear] = value;
// rear를 다음 위치로 이동 (원형 구조)
rear = (rear + 1) % capacity;
// 요소 개수 증가
++count;
return true;
}모듈러 연산을 사용하여 항상 큐의 유효한 인덱스를 가리키게 하는 것이 핵심이고,
가끔 가득 찬 큐인지 확인할 때, front = rear로 실수할 때가 있는데 이는 비어있는 경우도 해당되기 때문에
count와 capacity를 이용하여 확인하는게 맞다.
삭제
맨 앞의 원소를 삭제 후 삭제한 값을 반환한다.
bool pop(T& outValue)
{
// 비어 있는 큐인지 확인
if (count == 0) return false;
// front 위치의 값 저장
outValue = data[front];
// front를 다음 위치로 이동 (원형 구조)
front = (front + 1) % capacity;
// 요소 개수 감소
--count;
return true;
}
접근
// 큐의 맨 앞 요소를 제거하지 않고 확인
const bool front(T& outValue) const
{
// 비어 있는 경우 접근 불가
if (count == 0) return false;
// front가 가리키는 요소 저장 후 종료
outValue = data[front];
return true;
}
'코딩 테스트 > 자료구조' 카테고리의 다른 글
| Stack (0) | 2026.01.12 |
|---|---|
| Linked List (0) | 2026.01.07 |
| Vector (1) | 2026.01.07 |
| String & Vector (0) | 2025.05.18 |
| 힙 [Heap] (0) | 2022.07.29 |