

문제
문자열 배열이 주어지고, 각 Anagrams의 집합을 반환한다.
※ Anagrams : 단어를 이루고 있는 알파벳의 수와 종류가 같은 것
시간 복잡도
먼저 가장 생각하기 쉬운 $O(n^2)$는 100'000'000으로 아슬아슬하기 때문에 최선책을 더 찾아본다.
$O(n \log{n})$의 경우는 대략 10000 * 10 = 100'000으로 충분히 가능해 보이기 때문에, $O(n \log{n})$의 복잡도 아래로 진행하는 방식으로 생각해 봤다.
해결 계획
우선 집합을 어떻게 만들 것인가에 대해 고민했다.
- 알파벳의 아스키코드 값을 더하여 key로 사용한다 = $O(n)$
시간은 빠르긴 한데, 다른 알파벳 구성에서 같은 key값이 나올 수 있기 때문에 제외한다. - 단어를 사전순으로 정렬한 값을 key로 사용한다 = $O(n \log{n})$
충분히 가능한 것 같아 해당 방법을 이용한다.
예상에서 벗어나는 입력값은 없어서 바로 진행하기로 했다.
구현
크게 어려운 부분은 없다.
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string,vector<string>> table;
vector<vector<string>> result;
result.reserve(strs.size());
// 문자열 배열 순회
for (const string& data : strs)
{
// 단어 정렬해서 key값 만들기
string key = data;
sort(key.begin(), key.end());
// 키에 값 삽입
table[key].push_back(data);
}
// 각 키마다 들어간 값들 vecrtor에 삽입하여 반환
for (const auto& data : table)
{
result.push_back(data.second);
}
return result;
}
되돌아보기 & 개선 코드
글을 작성하면서 첫 번째 해결 방법인 O(n)으로 어떻게든 안될까?! 생각해 보다가,
뭔가 잘하면 될 거 같은데?라는 생각이 들어서 구현해 보았다!
문자열을 카운트로 사용하는 방법인데, 정확히는 문자열의 각 문자 char형을 카운트로 사용하는 방법이다.
"aab"라면 아래와 같이 표현 가능하다.

이런 방식은 "baa" 혹은 :"aba"도 같은 key를 가진다. 즉, 같은 Anagrams를 가진 문자열을 하나의 key로 묶을 수 있게 됐다.
고려해 볼 것은 카운트를 얼마나 할 수 있는가가 쟁점이었는데, 다행히 각 문장의 길이가 최대 100 이하이기 때문에,
같은 알파벳 100개가 나와도 하나의 char로 카운트가 가능했다.
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string,vector<string>> table;
vector<vector<string>> result;
string key(26, 0);
// 문자열 배열 순회
for (const string& data : strs)
{
memset(key.data(), 0, key.size());
// 문자 카운트 하면서 키 생성
for (char c : data)
{
key[c - 'a']++;
}
// 생성된 키에 값 추가
table[key].push_back(data);
}
// 각 키마다 들어간 값들 vecrtor에 삽입하여 반환
for (auto data : table)
{
result.push_back(data.second);
}
return result;
}
위의 코드는 $O(n)$의 복잡도를 가진다.
근데 결과는 생각보다 비슷했는데, 복잡도를 계산해 보면 이러하다.
문자열의 길이를 L이라 표현할 때,
기존 코드의 실제 시간 복잡도는 $O(n \times L \log{L})$ 이다.
개선된 코드의 실제 시간 복잡도는 $O(n \times L)$ 이다.
여기서 n은 같으니 실제 비교 대상은 $L \log{L}$ 와 L이 된다.
문제 조건에서 L은 최대 $100$이기 때문에,$L \log{L} \approx 100 \times 6.64 \approx 664$ 와 $100$ 을 비교하면 된다.
664와 100은 이론적으로 6배 이상 차이가 나야 하는데 아니 비슷한 이유는 진짜 뭐지??????????
이럴 리 없다
결과가 예상 복잡도와 너무 멀기 때문에 실제로 한 번 테스트를 수행했다..;
테스트 코드
#include <iostream>
#include <vector>
#include <string>
#include <unordered_map>
#include <algorithm>
#include <chrono>
#include <random>
using namespace std;
/////////////////////////////////////////////////////////
// Sort 방식
vector<vector<string>> groupAnagramsSort(vector<string>& strs)
{
unordered_map<string, vector<string>> table;
for (const string& data : strs)
{
string key = data;
sort(key.begin(), key.end());
table[key].push_back(data);
}
vector<vector<string>> result;
result.reserve(table.size());
for (auto& kv : table)
result.push_back(kv.second);
return result;
}
/////////////////////////////////////////////////////////
// Count 방식
vector<vector<string>> groupAnagramsCount(vector<string>& strs)
{
unordered_map<string, vector<string>> table;
string key(26, 0);
for (const string& data : strs)
{
fill(key.begin(), key.end(), 0);
for (char c : data)
key[c - 'a']++;
table[key].push_back(data);
}
vector<vector<string>> result;
result.reserve(table.size());
for (auto& kv : table)
result.push_back(kv.second);
return result;
}
/////////////////////////////////////////////////////////
// 랜덤 문자열 생성
vector<string> makeTest(int n, int L)
{
vector<string> v;
v.reserve(n);
static random_device rd;
static mt19937 gen(rd());
uniform_int_distribution<> dist(0, 25);
for (int i = 0; i < n; i++)
{
string s;
s.reserve(L);
for (int j = 0; j < L; j++)
s += char('a' + dist(gen));
v.push_back(s);
}
return v;
}
/////////////////////////////////////////////////////////
// 시간 측정 함수
template<typename Func>
double measure(Func f, vector<string> data)
{
auto start = chrono::high_resolution_clock::now();
f(data);
auto end = chrono::high_resolution_clock::now();
return chrono::duration<double, milli>(end - start).count();
}
/////////////////////////////////////////////////////////
// 메인 테스트
int main()
{
vector<int> lengths = { 3, 10, 50, 100, 200};
int n = 10000;
for (int L : lengths)
{
cout << "============================\n";
cout << "n = " << n << ", L = " << L << "\n";
auto testData = makeTest(n, L);
double sortTime = measure(groupAnagramsSort, testData);
double countTime = measure(groupAnagramsCount, testData);
cout << "Sort 방식 : " << sortTime << " ms\n";
cout << "Count 방식 : " << countTime << " ms\n";
}
return 0;
}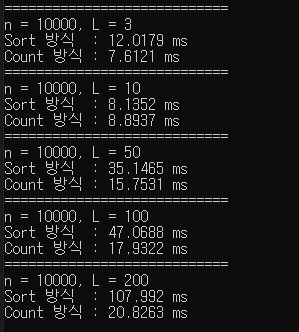
L이 작으면 큰 차이는 없지만, L이 커질수록 Count 방식이 훨씬 빠른 경향을 보이는 걸 알 수 있었다
char형은 256까지만 카운트가 가능하지만 더 큰 값으로 Count를 해야 한다면 배열로 변경해 사용하면 될 듯하다!
'코딩 테스트 > 알고리즘 풀이' 카테고리의 다른 글
| [Leet code - 739] Daily Temperatures ✅ (0) | 2026.02.26 |
|---|---|
| [Leet code - 20] Valid Parentheses ✅ (0) | 2026.02.26 |
| [Leet code - 75] Sort Colors ✅ (0) | 2026.02.13 |
| [Leet code - 347] Top K Frequent Elements ✅ (0) | 2026.02.12 |
| [Leet code - 217] Contains Duplicate ✅ (0) | 2026.02.10 |
| [Leet code - 1] Two Sum ✅ (0) | 2026.02.09 |
| [백준 - 1018] 체스판 다시 칠하기 ✅ (0) | 2026.02.02 |
| [다익스트라] 연습 문제 (0) | 2025.09.06 |