

#include <iostream>
#include <algorithm>
using namespace std;
int arr[100'002];
int BinarySearch(const int * arr, const int & size, const int & f)
{
int s = 0, e = size - 1, m;
while (s <= e)
{
m = (s + e) / 2;
if (arr[m] == f) return 1;
if (arr[m] < f) s = m + 1;
else e = m - 1;
}
return 0;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
int N; cin >> N;
for (int i = 0; i < N; ++i)
{
cin >> arr[i];
}
sort(arr, arr + N);
int M,F; cin >> M;
for (int i = 0; i < M; ++i)
{
cin >> F;
cout << BinarySearch(arr, N, F) << "\n";
}
return 0;
}||사고 과정
단순 이분탐색을 사용하는 문제,
직접 구현하여 풀이했다.
||사용 기법
- Binary Search
||더 간단한 풀이
#include <iostream>
using namespace std;
int arr[100'002];
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
int N; cin >> N;
int temp;
for (int i = 0; i < N; ++i)
{
cin >> temp;
arr[temp] = 1;
}
int M,F; cin >> M;
for (int i = 0; i < M; ++i)
{
cin >> F;
cout << (arr[F] == 1 ? 1 : 0) << "\n";
}
return 0;
}이런식으로 정렬 없이 할 수 있을것 같아서 생각해봤지만 들어오는 수의 범위가 int형이므로
int형의 범위만큼 배열을 정의할 수 없기에 비슷한 동작인 Set을 사용해볼것이고
그 중 항상 100% 안정성이 있지는 않지만 빠른 unordered_set을 사용해보았다.
#include <iostream>
#include <unordered_set>
using namespace std;
unordered_set<int> S;
int main()
{
ios::sync_with_stdio(0), cin.tie(0);
int N; cin >> N;
int temp;
for (int i = 0; i < N; ++i)
{
cin >> temp;
S.insert(temp);
}
int M,F; cin >> M;
for (int i = 0; i < M; ++i)
{
cin >> F;
cout << ((S.find(F) == S.end()) ? 0 : 1) << "\n";
}
return 0;
}여기서 놀라웠던건 시간인데
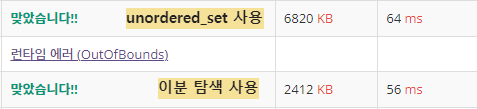
상수시간을 가지는 u_set보다 n log n의이분탐색이 더 빠르게 나왔다.
O(1)과 O(log N)에서 시간복잡도에 붙은 상수로 자주 뒤집어질수있다고 한다.
항상 상수를 떼고 계산하다보니까 그럴수도 있다는 생각을 하지 못했다.
글 읽기 - HashMap이 이분탐색보다 느린 이유가 뭔가요?
댓글을 작성하려면 로그인해야 합니다.
www.acmicpc.net
'코딩 테스트 > 알고리즘 풀이' 카테고리의 다른 글
| [백준 - 1182] 부분수열의 합 (0) | 2022.08.27 |
|---|---|
| [백준 - 9663] N-Queen (0) | 2022.08.27 |
| [백준 - 1074] Z (0) | 2022.08.26 |
| [백준 - 18870] 좌표 압축 (0) | 2022.08.25 |
| [백준 - 2156] 포도주 시식 (0) | 2022.08.24 |
| [백준 - 9465] 스티커 (0) | 2022.08.23 |
| [백준 - 11057] 오르막 수 (0) | 2022.08.23 |
| [백준 - 1543] 문서 검색 (0) | 2022.08.23 |